
manifest與snapshot就像 Iceberg 的「目錄」與「時光機」,分別負責掌管檔案的組織結構,以及資料在不同時間點的全貌。
首先談談 manifest 的用途,他還可幫助 查詢引擎 進行:
*條件下推 (Predicate Pushdown):指使查詢條件(如 WHERE age > 30)被「下推」
至儲存層來做早期過濾,而不是等資料全讀進來才篩選。*分區裁剪 (Partition Pruning):當表格是依某欄位做 partition(分區)時
查詢條件中若有使用該欄位,就可以只讀取符合的分區,跳過其他無關分區的資料。
再說下 snapshot 的用途,透過保存各時點的快照檔可以做到:
那到底 snapshot 快照檔與 manifest 是如何對應的呢?
答案是,每個 snapshot 對應一或多個 manifest list(manifest-list-xxx.avro),每個 manifest list 又指向多個 manifest,如下圖:
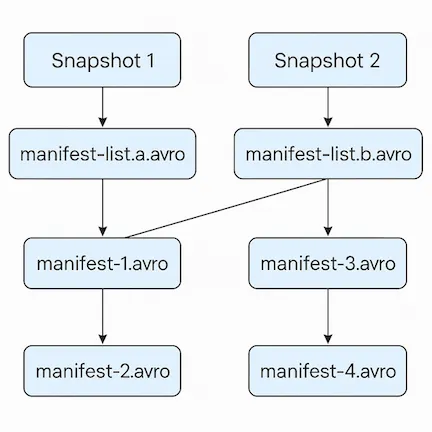
這樣最終就會指到實體資料的位置,構建出完整的索引系統。
# snapshot to data files
Snapshot
└── Manifest List(manifest-list-xxx.avro)
└── Manifest Files(manifest-xxx.avro)
└── Data Files(data/*.parquet)
使用 S3 實際說明了 Iceberg 的特性後,是時候拉回正題,也就是到底要如何在資料湖倉上發揮 Iceberg 的好處呢?
說到這需回顧系列文 — 《效能跟一致性? 資料湖倉全都要!》內提到資料湖倉解決的資料倉儲痛點,包含:
-- 計算總付款金額
SELECT
order_transactions.*,
(
SELECT
SUM(
COALESCE(TRY_CAST(JSON_EXTRACT(payment, '$.payment_fee.cents') AS DOUBLE), 0)
) AS payment_fee
FROM
UNNEST(order_transactions.payments) AS t(payment)
) AS payment_fee
FROM
updated_data
INNER JOIN
iceberg.datalakehouse_elt_silver.mongo_shopline_order_transactions AS order_transactions
ON
updated_data.order_transaction_id = order_transactions.order_transaction_id
WHERE
order_transactions.status = 'active'
AND COALESCE(order_transactions.order_status, '') != 'temp'
AND order_transactions._processed_at IS NOT NULL
系列文明日《冰山不止一角,Iceberg 與 S3 (三)》,將延續前文主題,帶你走進 Trino + Iceberg on S3 的實際運作流程,同時揭開 Trino 讀取 Iceberg 的細節與秘辛。
My Linkedin: https://www.linkedin.com/in/benny0624/
My Medium: https://hndsmhsu.medium.com/

